
Reply to comment
What’s the difference between a boxplot and an x-ray? Visualisation and Processing
Wed, 29/08/2012 - 12:47 — danA repost of my first blog entry on the Talisman blog, trying harder to understand visualisation and communication.
--
This article is the first of a few I hope to write about visualisation and Processing, a graphics tool created by Ben Fry and Casey Reas back in 2001. In this one I'll introduce Processing and get into some hard-core navel-gazing about visualisation. Next time I'll look at ways to use the Processing library as part of larger Java projects, where I'll assume some knowledge of Java and the Netbeans IDE. We can then move on to some fruitful combination of coding and chin-stroking. I'll also be attending the Guardian's data visualisation masterclass and will report back.
Communication and visualisation in research is both absolutely essential and mired in misunderstanding. It's essential, of course: all research needs to communicate its findings. Ideally, we want that communication to be effective. In some fields, communication is not only vital but fraught: the science of climate change faces concerted attempts to distort its output, and some wonder whether researchers are the best people to deal with this.
So what works? And, maybe more importantly, what doesn't work - and why not? The misunderstanding is perhaps quite simple: we think all images are equal. They enter the eye the same for everyone, don't they? Well, no. This post looks at some of these complexities by talking about four different static images: an x-ray, a box-plot, a mind-map and a simple graphic from the Guardian.
I'm writing this very much as a keen learner. I've been using Processing for a number of years in research projects, but still feel a long way from achieving the communication goals I've aimed for. As with all research, it's too easy to get stuck in silos where the only feedback is the echo of your own voice. Communication and visualisation are so vital, and its methods changing so rapidly, it seems like an ideal topic for the Talisman blog. Processing is a tool many researchers are dabbling with, and it presents an excellent opportunity to dig into the subject.
The Processing website itself is a wonderful learning resource - there's no point me duplicating what's there. Processing is an ideal starting point for learning to code. It can function as "Java with stabilisers on" but also works brilliantly on its own terms. The learning page on their site has everything from a basic introduction for non-programmers through to some working code examples of vector and trig maths and a lesson in object-oriented programming (OOP).
As Ben Fry explains, the philosophy of Processing is built around the 'sketch'. As he says, "don't start by trying to build a cathedral":
Why force students or casual programmers to learn about graphics contexts, threading, and event handling functions before they can show something on the screen that interacts with the mouse?
He also suggests that people new to Processing spend some time in its own editor (this comes with the download) and have a go "sketching" before venturing further.
In the next article where I'll look at using Processing with Netbeans, we'll go in exactly the opposite direction: providing foundations for building more elaborate structures. But I've found that I still return to writing 'sketches' to check out some quick idea - it's very easy and pleasing to code, and has the advantage that you can get a web-ready applet with one click (and perhaps a little HTML editing if you want to provide more explanation, as I did here).
Exporting from Processing's own editor automatically includes a link to the source code at the bottom - this is very much part of Processing's open source, sharing philosophy. openprocessing.org is a nice place to look for new sketches, including code. My current favourites there: this and this Turing pattern visualisation.
Ben and Casey's creation has taken on a life of its own. A look through the pages of the site's exhibition gives a sense of the range. For sheer visual genius, here's a few of my all-time favourites: the commit history of Python, moving from one or two contributors to a quite sudden explosion in popularity, really giving a sense of the scale of input that goes into this kind of project (and how open source underpins that); and three music videos, Music is Math coded by Glenn Marshall and a couple of variations on a theme, visualisations for a Goldfrapp and Radiohead track by 'Flight404'.
As a colleague said after seeing these, "I didn't know Java could do that." Quite. As Steven Johnson discusses in his book, 'where good ideas come from', platforms are vital to innovation and development. When first looking at what people have achieved with Processing, I think it's quite common to look for the fancy functions achieving it. There aren't any - rather, Processing is a platform that enables these things to be done by empowering people's coding creativity. Which is not to say there aren't fancy things Processing can do - there are - as well as many excellent 3rd party libraries, but you're still required to get in there and code the detail.
Academic users of Processing (of which there are many) tend to be rather more shy of publicising how they're using it. I've heard reports from conferences of it being used, but you won't see it directly mentioned very often. However, it certainly is being used by many people, including some at CASA. Processing.org's exhibition has a few examples, some with an added dash of geography: a tube travel time map that rearranges based on your station of choice; a University of Madrid project visualising sources of air pollution over the city and another Madrid example looking at car use; Max Planck research networks combining collaboration networks and geography; an attempt to communicate the the scale of modern migration; and non-mappy ones including this 'tool for exploring the dynamics of coastal marine ecosystems' and a New York Times project visualising social media propagation.
What were the intentions behind these projects? They vary, of course, but I think often even the creators themselves have not been completely clear. Ben Fry makes a very good point in his book, visualising data: it is easy to confuse pleasing-looking graphics with communication. If the goal is to successfully allow the viewer to grasp some dataset in a way they couldn't otherwise, a profusion of visual complexity may well achieve the opposite.
But communication is a subtle thing: the Python commit video communicates a visceral point that would otherwise have been completely invisible: you can see how a large coding project developed. That's achieved through quite innocuous-seeming coding choices like allowing 'file commits' to fade at a given rate. And the point is clearly not to allow the viewer to access information in a more powerful way (in the sense that one would access information in a database).
In comparison, the marine ecosystem visualisation, while clearly having a great deal of depth, has a communication problem. (I say this as a researcher who, I think, has faced a very similar set of problems, so I'm, um, critically sympathising rather than passing judgement!) Perhaps only the coder is in a position to understand it fully. They developed the code and their perceptual understanding of the output in tandem, finishing up with a default grasp of its workings unavailable to others. This process may actually have made it more difficult for them to know what it's like for a newcomer looking at the display and controls for the first time.
What's useful as a researcher/coder, then, can be quite different from what is informative for others. This is an important use of visualisation coding that is rarely talked about, and has been very useful to me: finding new ways to understand your own work.
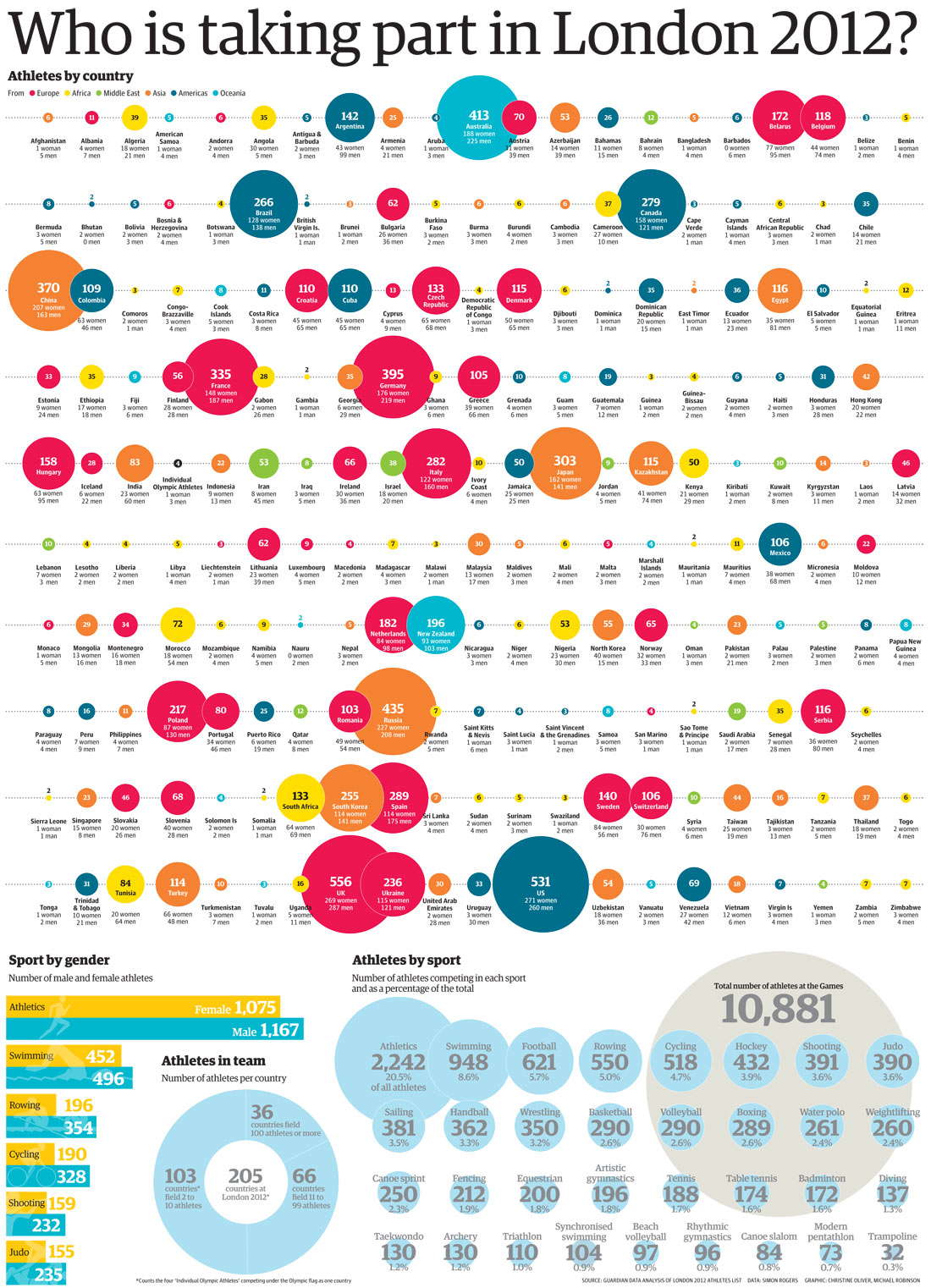
To try and untangle what's going on here, let's get onto those four static images - each a different types of visual information. An x-ray, a box plot, a mind-map and this recent graphic from the Guardian showing how many athletes from each country took part in the London 2012 olympics.
{kind=link}
Alan Chalmers talks about x-rays in the classic philosophy of science book, 'what is this thing called science?', quoting Michael Polanyi's description of a medical student getting to grips with them:
At first, the student is completely puzzled. For he can see in the x-ray picture of a chest only the shadows of the heart and ribs, with a few spidery blotches between them. The experts seem to be romancing about figments of their imagination; he can see nothing that they are talking about. Then, as he goes on listening for a few weeks, looking carefully at ever-new pictures of different cases, a tentative understanding will dawn on him. He will gradually forget about the ribs and see the lungs. And eventually, if he perseveres intelligently, a rich panorama of significant details will be revealed to him; of physiological variations and pathological changes, of scars, of chronic infections and signs of acute disease. He has entered a new world. (Polanyi 1973 p.101 in Chalmers p.8)
Chalmers is making two points about scientific observation, but they're equally applicable to visualisation. First, what people see "is not determined solely by the images on their retinas but depends also on experience, knowledge and expectations." In the x-ray case, "the experienced and skilled observer does not have perceptual experiences identical to those of the untrained novice when the two confront the same situation." Quite the reverse: the mind must be guided to a point where previously invisible information begins to become legible.
I've picked the box-plot as an archetypal example of a statistical visualisation that makes sense to the initiated. Is the difference between a box-plot and an x-ray only a matter of degree? I'd say it was qualitatively different. Consider someone looking at a box-plot after a long absence from statistics. They could plausibly refresh their understanding with a quick glance over the wikipedia page. Unlocking the meaning of the visualisation is much more accessible to simple reasoning and straightforward study - there's no need to develop an entirely new perceptual toolbox in your head. That's not to say that you can't develop perceptual tools unique to reading statistics - but while it would be possible to learn boxplot interpretation from solitary study, it would take quite a different process to build the structures in your head needed for x-rays. The key phrase is "looking carefully at ever-new pictures of different cases" while an expert explains what they're seeing. A new ability to see is pieced together though many guided associations over time.
That difference also applies to mind-maps. The article I linked to above included this image of mind-map notes from a lecture. Many people (myself included) probably have old mind-maps that were the culmination of note-taking for exams or essays. They make pretty much zero sense to anyone else. They probably don't make much sense to the person who made them after enough time has elapsed. But that's fine - the purpose of the mind-map isn't direct visual communication, it's the visual tip of a perception-forming iceberg. The process of making it is at least as crucial as the outcome. It isn't meant to make sense to anyone else. This is the reason I'd argue projects like debategraph are not really effective. If you want to understand Tim Jackson's 'prosperity without growth' (here's the debategraph version), we already have a much better, test-hardened interactive communication tool that's perfect for dealing with complex, interconnected concepts: the book.
{kind=link}
So mind-maps are like x-rays: there's a process of perception formation that must be gone through. But they're also not like x-rays. You're not learning to see the information the picture contains, but creating those perceptions in the first place - and there's something about the active process of making them that's vital to that. When the person who made the mind-map looks at it, it's plugging into all the linked concepts developed in the mind, in part by the process of making it. With a mind-map, visualisation and perception development are a feedback system.
In stark contrast to all that, there's the Guardian's graph of athlete numbers (here's a permalink in case it moves...) It's meant to communicate, as quickly, intuitively and transparently as possible, a large quantity of numbers - and succeeds. It uses a concept we're already primed to understand: relative size. You don't even need a key (it's only just occurred to me what an apt word that is.)
{kind=link}
Returning to the marine ecosystem example: I suspect the process of coding it did something to reinforce the perceptions the coder had of the system being modelled. It was - like the mind-map process - a feedback. When they play with the parameters, that keys into their understanding in a way that is very difficult for anyone else. And - as with all the examples I've just discussed - that's an entirely valid and useful role. But it's also not the same as communicating information to a new audience. It's not even the same as communicating information to the initiated. That use of visualisation - as with the mind-map - isn't about communication at all. Its purpose is to develop the understanding of the person creating it.
A box-plot can't form part of that kind of feedback loop in the same way - but it can do two jobs a mind-map can't. You can produce box-plots that make sense to you, and can be used to communicate a summary to others who share that common language. This isn't true of all visualisations, for the obvious reason that if you've created it yourself, you are probably not conforming to agreed standards of meaning. You're making it up as you go along (though hopefully, as with the Guardian graphic, using commonly understood visual cues). But there's also the added element common to x-rays and mind-maps: the perceptual tools we actively create through a process of development may exist only in our own minds. This doesn't mean we can't communicate our findings - it just means communication is a separate job and needs to be given its own consideration.
I'll come back to this subject in a later post by taking a look at my PhD work that used Processing. Building interactive visualisation tools helped me to develop my own insights - but plugging those visualisations directly into the thesis did not go down very well! The stuff I've just discussed is, in part, me working out what went wrong: the feedback process for my own research was one thing, communication should have been another.
But the next article will take a break from all this navel-gazing and explain how to get Processing set up as part of a Netbeans project, as well as looking at ways to turn data into visuals.
Recent comments
21 weeks 6 days ago
2 years 12 weeks ago
2 years 12 weeks ago
2 years 14 weeks ago
2 years 15 weeks ago
2 years 15 weeks ago
3 years 12 weeks ago
3 years 36 weeks ago
3 years 36 weeks ago
3 years 38 weeks ago